

How I built a €25K Machine Learning Rig
How I built a €25K Machine Learning Rig
How to plan, buy, build, and store your 2-10 GPU machine learning servers and PCs

Below is my first beauty.
It has 4 NVIDIA RTX A6000 and an AMD EPYC 2 with 32 cores, including 192 GB in GPU memory and 256GB in RAM (part list).

Let’s begin.
GPUs
Until AMD’s GPU machine libraries are more stable, NVIDIA is the only real option. Since NVIDIA’s latest Ampere microarchitecture is significantly better than the previous generation, I’ll only focus on Ampere GPUs.
NVIDIA has three broad GPU types:
Consumer: (RTX 3080 / RTX 3090)
Prosumer: (A6000)
Enterprise: (A100)
There are a few convenient GPU amounts per rig and consumer class:
Consumer: two RTX 3080s/RTX 3090s
Prosumer: four A6000s
Enterprise:
8 A100 or A6000 (PCIe),
16 A100s (SXM4), and
20 A100 (PCIe-based modular blade nodes).
You can work around these limits, but it increases risk, reliability, and convenience.
Constraints For Consumer GPUs
Let’s outline a few of the limitations for the consumer and prosumer cards.
Main limits:
Motherboard limit with PCIe risers: 14 GPUs (x8 Gen 4.0 per GPU)
Consumer electricity limit per socket: 8 GPUs (4 in the US)
Consumer power supply limit: 5 GPUs (2000W)
Standard PC case size: 4 dual-slot GPUs
Space and environment limits:
Stacking cards next to each other: 4 A6000/3070 or 2 3080/3090
Shared office sound and heat limit: 2 GPUs (preferably water-cooled)
Consumer supply per customer: 1 GPU (most stores will only allow you to buy one consumer GPU, and they are only generally available 3-12 months after launch)
I tried to buy 5 RTX 3090, but after waiting four months due to supply issues, I opted for four RTX A6000.

According to Lamda Labs and Puget Systems, the 3080 and 3090 dual-slot blower editions are too hot to reliable fit four next to each other on a standard-sized motherboard. Thus you need PCIe risers, a water-cooled rig, or cap the power usage.
Using PCIe risers in an open-air rig exposes the hardware to dust. A water-cooled rig requires maintenance and has a risk of leaking during transportation. Capping power usage is non-standard and could lead to unreliability and performance loss.
For 3+ GPU rigs, many opt for cards that consume 300W or less, so the RTX 3070 and down or A6000 and up.
Most of today’s models are designed for 16GB cards since the most mainstream cloud GPUs have 16 GB GPU memory, and we are shifting towards 40 GB. Thus, the cards with the lowest memory will see an increased overhead in rewriting software to accommodate a lower memory limit.
Why do I see 8-GPU consumer rigs online?
The 5+ GPU consumer rigs people see online are often crypto-rigs with multiple power sources.
Since crypto-rigs don’t need high bandwidth, they use specific USB adapters to connect the GPU. It’s an adapter that transfers the data without electricity. Thus, the GPU and motherboard’s power is separated, which reduces the problem of mixing circuits.
However, the adapters are often of poor quality, and a small soldering error can both destroy your hardware and catch fire. And they are especially not recommended for ML rigs that require PCIe risers that enable 75W of power.
Crypto rigs also use mining power supplies from Alibaba with poor standards or retrofit enterprise power supplies. Since people tend to place them in garages or containers, they accept the added safety risk.
Prosumer and Enterprise Features
For the Ampere series, NVIDIA makes it hard to use high-end consumer cards for workstations with more than 2 GPUs. The 3-slot width, high wattage, and seeing several manufactures discontinue the 2-width blower edition of the 3090 — all indicate this.
Thus, the prosumer and enterprise Ampere cards' key selling point is support for 3+ GPU rigs with 24/7/365 workloads.
The pro-consumer and enterprise cards have a few additional features.
Main features (compared to RTX 3090):
1.1 - 2 times faster (depending on GPU, binary floating-point formats, and model)
1.7 - 3.3 times more memory
Less energy consumption (better for stacking cards)
Datacenter deployment (non-profits can gain permission for consumer cards)
Nice to have features:
ECC memory (error-proof memory)
Multiple users per GPU, MIG (only enterprise cards)
Faster GPU-to-GPU communication, NVSwitch (A100 SXM4)
The 80GB GPUs will give you an edge for specific models, but it’s hard to say if they have enough compute to effectively benefit from the massive models. The safest option is the 40GB version. However, it’s hard to ignore the bragging rights that come with 80GB GPUs.
In general, I don’t think in terms of NLP, CV, or RL-specific workloads. They will vary in performance, but since the machine learning landscape is shifting so fast, it’s not worth over-optimizing for a specific workload.
For a more in-depth comparison, read Tim Dettmers’ go-to GPU guide. Pay extra attention to the Tensor Core overview, sparse training, capping GPU wattage, and low-precision computation.
Server Constraints
While the power supply caps the consumer rigs, server rigs are constrained in weight, case size, and networking overhead.
Main limits:
Server with consumer parts: 4 PCIe GPUs
PCIe server case limit: 10 dual-slot GPUs (the width of a standard server)
Transporting a server manually: 10 PCIe GPUs or 4 SMX4 GPUs (30kg)
Additional limits:
PCIe server case limit with networking: 8 dual-slot GPUs (2 dual-slots for networking)
SXM4 server case limit: 16 GPUs (168 kg)
PCIe blade server limit: 20 dual-slot GPUs
The key constraint here is networking overhead. As soon as you connect one or more servers, you need software and hardware to manage the system. I highly recommend Stephen Balaban's overview of building GPU clusters for machine learning.
The second key concern is weight and repairing.
A server with eight SXM4 sits at around 75kg. Thus you ideally need a server lift. The SXM4 can be hard to repair than the more standard parts that come with a PCIe server.
The A100 and A6000 also have versions without a built-in fan. These need a server case with a dozen 10K+ RPM fans. These will make them more fault-tolerant since you can hot-swap the fans.
Speed Benchmarks
Lambda Labs has the best per GPU benchmarks and overall benchmark.
The benchmark is the average of several models using PyTorch with half-precision.
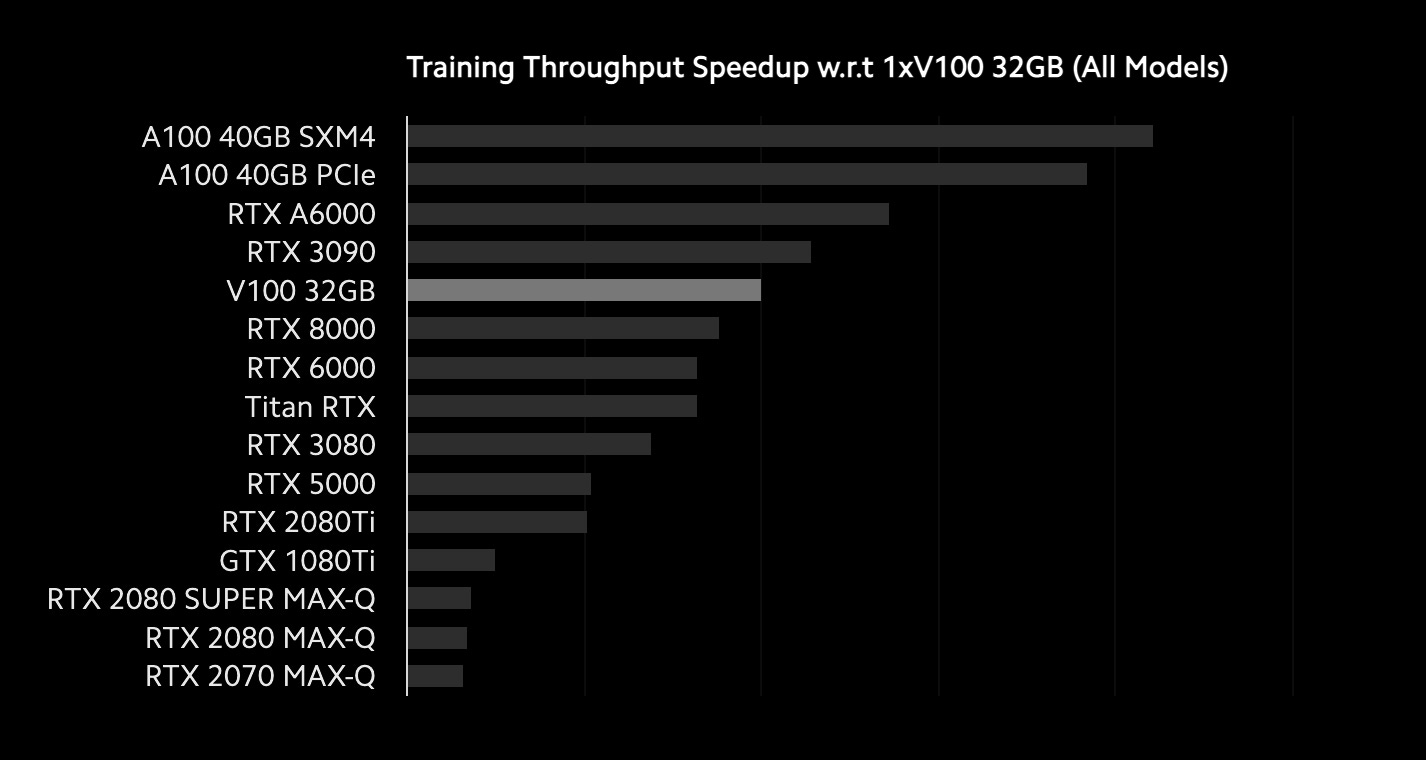
In terms of speed, the A100 is 1.4 times faster than the A6000. But the A6000 is 1.2 faster than the 3090, and twice as fast as the 3080.
The other noteworthy benchmark is the comparison between PCIe and SXM4. NVIDIA’s A100 PCIe can only connect to another GPU, while NVIDIA’s A100 SXM4 can simultaneously connect to 8 - 16 GPUs.

NVIDIA’s NVswitch and SXM4 have 10x faster bandwidth in theory, but in an 8-GPU setting, it’s only 10% faster when compared to PCIe solutions. Since the SXM4 is 8% faster on a per GPU basis, the NVswitch has a marginal impact.
It should be a marginal difference up to an 8-GPU system. According to Lamda Labs’ CEO, they can see a 2x improvement for certain use cases in larger clusters. Hence, it’s directed chiefly for multiple 8-GPU systems. It’s also worth looking into the DGX A100 SuperPOD system at the scale of several hundred GPUs.
Also, in networking benchmarks, pay attention to GB/s (Gigabytes) and Gb/s (Gigabits). GB/s is eight times faster than Gb/s.

GPU Pricing
The pricing is approximated for the actual retail price, rounded for simplification, and without VAT and discounts.
Enterprise:
A100 SMX4 (80 GB): €18k
A100 SMX4 (40 GB): €13k
A100 PCIe (40 GB): €9k
Prosumer and consumer:
RTX A6000 / A40 (48GB): €4500k
RTX 3090 (24 GB): €1500-2000
RTX 3080 (10 GB): €800-1300
RTX 3070 (12 GB): €700-1000
NVIDIA also provides startup and education discounts so that you can save 15-30% per GPU. For startups, apply to the inception program. In total, it takes about one week to get the discounts.
I saved around €4k on my 4 x RTX A6000 by building it and NVIDIA GPU discounts.
The SMX4 cards are sold as part of an 8 GPU server, so the per GPU pricing is a rough approximation due to the custom GPU-to-GPU communication that makes it more expensive.
Machine Learning Rig Tiers
These are estimated pre-built prices without discounts and VAT.
High-growth startups, large research labs, and enterprise:
€240-340k: 8 x A100 SXM4 (80 GB)
€120-170k: 8 x A100 SXM4 (40 GB)
Startups, research labs, and SMEs:
€90k: 8 x A100 PCIe (40 GB)
€50k: 4 x A100 PCIe or 8 x RTX A40 (fanless RTX A6000)
€25k: 4 x RTX A6000 (€21K if you build it and with GPU discounts)
€25k: 4 x RTX 3090 (Liquid cooling)
€15k: 4 x RTX 3090 (Crypto-style or capped perfomance)
Students, hobbyist, consultants:
€10k: 4 x RTX 3070
€7k: 2 x RTX 3090
€5k: 1 x RTX 3090 or 2 x RTX 3080
€4k: 1 x RTX 3080
€3k: 1 x RTX 3070
Budget is one aspect, but the key concern is where you place it.
When you start, you often have the machine in the same room and cope with the inconvenience.
As you scale, you’ll need more infrastructure. You might move it to a separate office room and later put it in a data center, starting with collocation and then climbing from tier 1 to 4 data centers for added fault tolerance.
I find 4 GPUs too loud and generate too much heat to have in an office or at home without proper cooling. Here’s a quick benchmark by Puget Systems. Think, a small leaf blower with hot air, equal to a 1600W radiator.
The starting price of a data center collocation is around €80-250 per GPU and month, including €25 per GPU in electricity charges. You can ask for a quote from all your local data center collocations here. If you plan on running workloads 24/7/365 on 4+ GPUs, I highly recommend it.
You can easily buy parts for a 4 GPU server, similarly to a PC. A barebone 5+ GPU ML server will cost around €7k.
CPU
Go with AMD.
AMD has 5x more internal bandwidth compared to Intel. And it’s both cheaper and better. A majority of the Ampere ML servers use AMD.
AMD has three main CPU types:
Consumer: (Ryzen 5000 with AM4 socket) and,
Prosumer: (Ryzen Threadripper 3rd Gen with sTRX4, and the sWRX8 socket for the 1st Gen Pro version)
Enterprise: (EPYC 2 with the SP3 socket)
For a 1-GPU system, Ryzen is excellent, and for systems between 2-4 GPU PCs, go with the Threadripper. For 5+ GPU systems and server builds, go with EPYC.
Threadripper is faster than EPYC, but EPYC has twice the memory channels, RDIMM, and requires less energy. If you plan to use your computer as a server, I’d go with EPYC.
I ended up with an AMD EPYC 2 Rome 7502P with 32 Cores. For the processors, I used eight cores per GPU as a rough guideline. Also, pay attention to if they support single, dual, or both processor setups.
CPU Cooling
For cooling, Noctua fans are the quietest, most performant, and reliable. However, I find the brown color scheme rather ugly. They are also big, so make sure they fit with your RAM and chassis.
For RGB fans, I enjoy Corsair’s All-in-one (AIO) liquid CPU coolers. They bring life. The colors are programmable, and the system frees up space around the CPU. They use antifreeze liquid, and the leak risk is tiny.
All Threadripper and EPYC CPUs have the same size, making the coolers compatible, but you might need a mounting bracket. Also, check that the cooler supports the wattage of the CPU you choose.
Anyways, here are my top pics:
Ryzen 5000: Noctua NH-D15 or Corsair H100i RGB PLATINUM
Threadripper: Noctua NH-U14S TR4-SP3 or Corsair Hydro Series H100x
EPYC: Dynatron A26 2U (for servers)
I avoid custom liquid cooling due to cost, maintenance, freezing risk, transport risk, and lack of flexibility.
Motherboard
Here are a few motherboards worth considering for AMD :
Ryzen 5000: MSI PRO B550-A PRO AM4 (ATX)
Threadripper 3rd Gen: ASRock TRX40 CREATOR (ATX)
Threadripper Pro: ASUS Pro WS WRX80E-SAGE SE (ETAX)
EPYC 2: AsRock ROMED8-2T (ATX) (My motherboard)
My principal deciding factors were the PCIe slots and IPMI.
If you plan on using your ML rig as a regular PC and want built-in support for, say, WIFI, headphone jack, microphone jack, and sleep functionality — you are best off with a consumer or prosumer motherboard.
In my case, I went with a dual-usage prosumer/server motherboard with support for remote handling or Intelligent Platform Management Interface (IPMI). Via an Ethernet connection and web GUI, I can install the OS, turn it on/off, and connect to a virtual monitor. An IPMI is ideal if you plan to use it 24/7/365.
CPU sockets have a built-in chipset, and the prosumer and consumer cards have additional chipsets to enable specific CPUs or features, for example, B550 for the Ryzen and TRX40 for the Threadripper.
For Ryzen 5000 builds it’s ideal to have a BIOS flash button. Otherwise, you need an earlier Gen Ryzen CPU to update the BIOS to be compatible with Ryzen 5000.
5+ GPU server-only motherboards are hard to buy separately. While consumer setups are modular, larger server builds are integrated.
Motherboard sizes
The standard size of a motherboard is ATX, it’s 305 × 244 mm, and works great for both server chassis and PCs. I mostly look at ATX boards, the standard size, to avoid any chassis spacing issues.

Some of the other form factors vary in size depending on the manufacturer so that you will be more limited in terms of chassis. It’s not a big deal for consumer chassis, but for server chassis, you don’t what the height to be more than the ATX’s 305 mm.
PCI Express (PCIe)
Below is the motherboard I went with, the AsRock ROMED8-2T (ATX)

The important thing to look for is the PCIe slots, where you plug the GPUs, the vertical gray slots above. Above, you have seven single-width slots.
The connection will be to the far right of the GPU. As you see, it’s a tight gap between the RAM slots and the first GPU.
When you have four dual-width GPUs on a 7-slot board, the 4th GPU will exceed the board's bottom. Thus, you need a PC or server chassis that supports 8 PCIe extension slots.
For two RTX 3090 triple-slot cards, you’d have the first card cover the first three PCIe slots and empty slot and have the second GPU cover the last three slots.
If you plan to buy an NVlink to connect two GPUs, they often come in 2-slot, 3-slot, and 4-slot versions. In the picture, you’d need two 2-slot bridges. For the triple-slot cards with a gap in between, you’d need a 4-slot bridge: the width of the card, 3-slot, plus the 1-slot gap.
There are a few things worth knowing about PCIe slots:
PCIe physical length: it’s x16 per slot in the picture, the standard for GPUs, which is 89 mm.
PCIe bandwidth: sometimes, you have the length of an x16 slot, but only half has pins that connect it to the motherboard, making it an x16 slot with x8 bandwidth. For reference, crypto-rigs will use x16 adapters but with x1 bandwidth.
Generation speed: The above board is Generation 4.0. Each generation tends to be twice as fast as the previous generation. NVIDIA’s latest GPUs are Gen 4.0 but have comparable performance on Gen 3.0 boards in practice.
Multiple GPU requirements: For 4-10 GPU systems, most recommend at least x8 Gen 3.0 per GPU.
PCIe lanes
Another thing most people look for is the total amount of PCIe lanes, the total internal bandwidth. It gives you a rough indication of the networking, storage, and multiple GPU capacity.
Motherboard manufacturers can use PCIe lanes to prioritize certain features, such as storage, PCIe slots, CPU-to-CPU communication, etc.
For reference, one GPU will use x16 lanes, a 10 GB/s ethernet port uses x8 lanes, and an NVMe SSD will use x4 lanes.
Here’s what AMD’s chipsets enable:
Ryzen 5000: 20 PCIe lanes Gen 4.0
Threadripper 3rd Gen: 88 PCIe lanes Gen 4.0
Threadripper Pro 1st Gen: 128 PCIe lanes Gen 4.0
EPYC 2: 128 PCIe lanes Gen 4.0
Chassis
The most used ML workstation chassis is Corsair Carbide Air 540, and for consumer servers, the Chenbro Micom RM41300-FS81. From a sound, dust, and transportation point of view, these two cases are ideal. Both will house the RTX 3090, but you need a rear-end power connector for the Chenbro.
{kind=link}
I started with the Thermaltake Core P5 Tempered Glass Edition. From an ascetic angle, it’s the best. But it’s rather clunky and not ideal for dust. Given the GPUs' heat and noise, I decided to convert it into the server with the Chenbro chassis and put it in a data center.
Space between the GPUs will have more impact than the main chassis airflow. If you are going for 3+ 3080/3090, you want to look into open-air crypto-rig setups. However, these are both very noisy and vulnerable to dust. Ideally, you want to put it in a sound-isolated room with cooling and dust filters.
The Chenbro chassis has two 120 mm 2700 RPM fans on the lid, which creates an excellent airflow for the GPUs.

PSU, RAM, and Storage
When you have the GPU, CPU, motherboard, and chassis — the rest of the components are easy to pick.
Power Supply: For power supply, I looked at the two suppliers considered the best, EVGA and Corsair. I added the total GPU wattage, an extra 250W, and a margin. Here’s a more accurate calculator. I ended up with the EVGA SuperNOVA 1600W T2.
RAM: I looked at what the motherboard provider recommended and bought something that I could easily buy online. It’s recommended to fill the available slots with RAM, and I wanted the RAM to match or exceed the GPU memory. According to Tim Dettmers, the RAM speed has little impact on the overall performance. I went with 8 x Kingston 32GB 3200MHz DDR4 KSM32RD4/32ME, so 256 GB.
NVMe SSDs: I checked the highest-rated SSDs on PCpartpicker and Newegg. I used 0.5 TB per GPU as a guideline with PCIe Gen 4.0. I grabbed two 2 TB Samsung 980 Pro 2 to M.2 NVMe.
Hard drives: I used the same strategy as my SSD, but 6 TB per GPU for slow storage. This ended up being 2 x 12 TB Seagate IronWolf Pro, 3.5'', SATA 6Gb/s, 7200 RPM, 256MB cache. For a more rigorous benchmark, you can study the disk failure rates.
NVlink: It’s a nice-to-have that can improve performance by a few percent on specific workloads. It does not combine the memory of two GPUs to a single memory, it’s just confusing marketing.
Purchases
PCpartpicker and Newegg are the most user-friendly price comparison tools.
Nowadays, if I can’t find it on Amazon, I think twice before buying something. Roughly 30% of the lesser-known stores gave me a headache.
A few examples:
Many stores don’t have the products they list online (5 stores)
The stores forgot my order, and I had to follow up for 3-9 weeks (3 stores)
One store sent me an order they had canceled and then charged me several hundred euros for the return (1 store)
One store didn’t send me the product for one month, and instead of making a refund, they gave me a voucher (1 store)
The customer service is either poorly automated or bad to the extent that it makes it unbearable to solve any issues (6 stores)
PNY lists the retailers of prosumer and enterprise cards. I reached out to all of the 20 suppliers in France. 50% didn’t reply. Of the replies, 60% didn’t have the latest cards, and from the quotes I got, the price varied between 5-10%. In France, CARRI systems had the best price and good customer service.
Build lists
PCpartpicker has more than 40 000 builds with the RTX 30 series, although most are with 1 GPU, some 2-GPU rigs, but nothing with 3+.
4 x RTX 2080 (Curtis will soon release a 4 RTX 3090 build)
Titan RTX, Intel (Article by Daniel Bourke)
One RTX 3090, Threadripper, Thermaltake Core P3 (Gorgeous!)
Pre-built rigs
Here are the providers per region that offer pre-built rigs.
Here's a list of retailers with transparent pricing:
EU
US
Lambda Labs (US)
Bizon (US)
Exxactcorp (US)
Puget Systems (US)
If you know of other providers that list prices, please submit them here, and I’ll add them.
Building and Installing
The hard part in building a rig is finding the parts, especially if you are trying to do something unconventional.
Putting the pieces together and installing them takes less than an hour, but you probably want to spend a few extra hours to be on the safe side.
I had a mobile repair kit at home that was useful, but you’ll be okay with a standard screwdriver and a good selection of bits.
I used the remote management system to install the software. When I plugged the ethernet cable into my router, it assigned it an IP address, then I put the IP address in the browser, and I had access to a web interface to update the BIOS and installed Ubuntu 20.04 LTS.
I then installed the Lambda Stack for all the GPU drivers and machine learning libraries, etc. I highly recommend it.
If you are using an IMPI, change the VGA output to internal in the BIOS. Otherwise, you can’t use the virtual monitor in the IMPI without removing the GPUs.
Conclusion
The main reason to own hardware is workflow. To not waste time on cloud savings and encourage robust experimentation.
You’ll save money when building a consumer ML rig. If you price your time, the cost savings of building prosumer and enterprise rigs is dubious. However, you’ll learn a bunch and become a much more educated consumer. Plus, it’s a valuable skill when all pre-built suppliers are having GPU supply issues.
Nvidia is making it hard to use high-end consumer cards for 3+ rigs. For a prosumer rig with a server room at home, I’d go for 4 x 3090 in an open-air rig. And with more limited space, a 2 x 3090 workstation.
With a larger budget, 4 x RTX A6000 is a good option, but given the noise and heat, I’d go for a server solution and place it in a data center.
The A100 has the most mindshare, but the A6000 / A40 is more value for money. The SMX4 is too clunky and offers a marginal performance gain over the PCIe version. I’d like to see a transparent benchmark with a large cluster to see the benefits in practice.
If you have any questions, ping me on Twitter, or drop a comment below.
Hi,
Can NVlink combine the memory of two GPUs to a single memory?
I am interested in purchasing a similar machine, with four A6000s. My recommended wattage with these and a threadripper is already at 1800W. What did you do to solve this issue?